1. Example running HBV for particle filter pre defining DA parameters (WIP)
setup packages
1 In:
# general python
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
import numpy as np
import os
from pathlib import Path
import yaml
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
import scipy
import xarray as xr
from tqdm import tqdm
import glob
from devtools import pprint
2 In:
# general eWC
import ewatercycle
import ewatercycle.forcing
import ewatercycle.models
3 In:
# pip install ewatercycle-HBV
set up paths
4 In:
path = Path.cwd()
forcing_path = path / "Forcing"
observations_path = path / "Observations"
figure_path = path / "Figures"
output_path = path / "Output"
forcing_path
4 Out:
PosixPath('/home/davidhaasnoot/eWaterCycle-DA/docs/Forcing')
Add parameter info
5 In:
## Array of initial storage terms - we keep these constant for now
## Si, Su, Sf, Ss
s_0 = np.array([0, 100, 0, 5])
## Array of parameters min/max bounds as a reference
## Imax, Ce, Sumax, beta, Pmax, T_lag, Kf, Ks
p_min_initial= np.array([0, 0.2, 40, .5, .001, 1, .01, .0001])
p_max_initial = np.array([8, 1, 800, 4, .3, 10, .1, .01])
p_names = ["$I_{max}$", "$C_e$", "$Su_{max}$", "β", "$P_{max}$", "$T_{lag}$", "$K_f$", "$K_s$"]
S_names = ["Interception storage", "Unsaturated Rootzone Storage", "Fastflow storage", "Groundwater storage"]
param_names = ["Imax","Ce", "Sumax", "Beta", "Pmax", "Tlag", "Kf", "Ks"]
stor_names = ["Si", "Su", "Sf", "Ss"]
# set initial as mean of max,min
par_0 = (p_min_initial + p_max_initial)/2
6 In:
experiment_start_date = "1997-10-01T00:00:00Z"
experiment_end_date = "1998-11-01T00:00:00Z"
HRU_id = 1620500
alpha = 1.26
Forcing
7 In:
from ewatercycle.forcing import sources
8 In:
camels_forcing = sources.HBVForcing(start_time = experiment_start_date,
end_time = experiment_end_date,
directory = forcing_path,
camels_file = f'0{HRU_id}_lump_cida_forcing_leap.txt',
alpha = alpha
)
import model
9 In:
from ewatercycle.models import HBV
import DA function (locally for now)
10 In:
import importlib.util
def module_from_file(module_name, file_path):
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
return module
11 In:
DA = module_from_file("DA",r'../src/eWaterCycle_DA/DA.py')
12 In:
n_particles = 100
setup model
13 In:
ensemble = DA.Ensemble(N=n_particles)
ensemble.setup()
14 In:
array_random_num = np.array([[np.random.random() for i in range(len(p_max_initial))] for i in range(n_particles)])
p_intial = p_min_initial + array_random_num * (p_max_initial-p_min_initial)
15 In:
# values wihch you
setup_kwargs_lst = []
for index in range(n_particles):
setup_kwargs_lst.append({'parameters':','.join([str(p) for p in p_intial[index]]),
'initial_storage':','.join([str(s) for s in s_0]),
})
17 In:
ensemble.initialize(model_name=["HBV"]*n_particles,
forcing=[camels_forcing]*n_particles,
setup_kwargs=setup_kwargs_lst)
18 In:
# create a reference model for easy access
ref_model = ensemble.ensemble_list[0].model
19 In:
ds = xr.open_dataset(forcing_path / ref_model.forcing.pr)
Import observations
20 In:
observations = observations_path / f'0{HRU_id}_streamflow_qc.txt'
21 In:
cubic_ft_to_cubic_m = 0.0283168466
22 In:
new_header = ['GAGEID','Year','Month', 'Day', 'Streamflow(cubic feet per second)','QC_flag']
new_header_dict = dict(list(zip(range(len(new_header)),new_header)))
df_Q = pd.read_fwf(observations,delimiter=' ',encoding='utf-8',header=None)
df_Q = df_Q.rename(columns=new_header_dict)
df_Q['Streamflow(cubic feet per second)'] = df_Q['Streamflow(cubic feet per second)'].apply(lambda x: np.nan if x==-999.00 else x)
df_Q['Q (m3/s)'] = df_Q['Streamflow(cubic feet per second)'] * cubic_ft_to_cubic_m
df_Q['Q'] = df_Q['Q (m3/s)'] / ds.attrs['area basin(m^2)'] * 3600 * 24 * 1000 # m3/s -> m/s ->m/d -> mm/d
df_Q.index = df_Q.apply(lambda x: pd.Timestamp(f'{int(x.Year)}-{int(x.Month)}-{int(x.Day)}'),axis=1)
df_Q.index.name = "time"
df_Q.drop(columns=['Year','Month', 'Day','Streamflow(cubic feet per second)'],inplace=True)
df_Q = df_Q.dropna(axis=0)
ds_obs_dir = observations_path / f'0{HRU_id}_streamflow_qc.nc'
ds_obs = xr.Dataset(data_vars=df_Q[['Q']])
if not ds_obs_dir.exists():
ds_obs.to_netcdf(ds_obs_dir)
23 In:
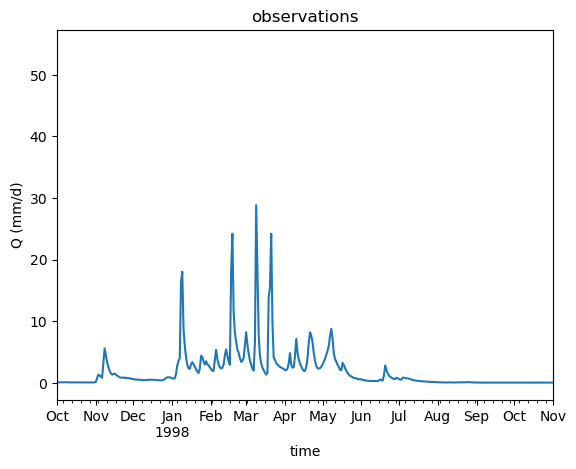
ax = df_Q['Q'].plot()
ax.set_xlim((pd.Timestamp(experiment_start_date),pd.Timestamp(experiment_end_date)))
ax.set_ylabel("Q (mm/d)")
ax.set_title("observations");
setup DA
This sets up all the require data assimilation information
24 In:
def H(Z):
if len(Z) == 13:
return Z[-1]
else:
raise SyntaxWarning(f"Length of statevector should be 9 but is {len(Z)}")
25 In:
ensemble.initialize_da_method(ensemble_method_name = "PF",
hyper_parameters = {
'like_sigma_weights' : 0.05,
'like_sigma_state_vector' : 0.005,
},
state_vector_variables = "all", # the next three are keyword arguments but are needed.
observation_path = ds_obs_dir,
observed_variable_name = "Q",
measurement_operator = H,
)
Run algorithm
In:
n_timesteps = int((ref_model.end_time - ref_model.start_time) / ref_model.time_step)
time = []
lst_state_vector = []
lst_Q = []
for _ in tqdm(range(n_timesteps)):
time.append(pd.Timestamp(ref_model.time_as_datetime.date()))
ensemble.update(assimilate=True)
lst_state_vector.append(ensemble.get_state_vector())
lst_Q.append(ensemble.get_value("Q"))
ensemble.finalize()# end model - IMPORTANT! when working with docker
WIP:
27 In:
Q_m_arr = np.array(lst_Q).T
state_vector_arr = np.array(lst_state_vector)
34 In:
Q_m_arr.T.shape
34 Out:
(396, 100, 1)
process the numpy data into easily acessed data types
28 In:
save = False
current_time = str(datetime.now())[:-10].replace(":","_")
40 In:
Q_m_arr[0,:,:len(time)].T.shape
40 Out:
(396, 100)
41 In:
df_ensemble = pd.DataFrame(data=Q_m_arr[0,:,:len(time)].T,index=time,columns=[f'particle {n}' for n in range(n_particles)])
process states and parameters into xarrys
42 In:
##### Save?
if save:
df_ensemble.to_feather(output_path /f'df_ensemble_{current_time}.feather')
43 In:
# if load:
# TODO: obtain from model
units= {"Imax":"mm",
"Ce": "-",
"Sumax": "mm",
"Beta": "-",
"Pmax": "mm",
"Tlag": "d",
"Kf": "-",
"Ks": "-",
"Si": "mm",
"Su": "mm",
"Sf": "mm",
"Ss": "mm",
"Ei_dt": "mm/d",
"Ea_dt": "mm/d",
"Qs_dt": "mm/d",
"Qf_dt": "mm/d",
"Q_tot_dt": "mm/d",
"Q": "mm/d"}
44 In:
data_vars = {}
for i, name in enumerate(param_names + stor_names):
storage_terms_i = xr.DataArray(state_vector_arr[:,:,i].T,
name=name,
dims=["EnsembleMember","time"],
coords=[np.arange(n_particles),df_ensemble.index],
attrs={"title": f"HBV storage terms data over time for {n_particles} particles ",
"history": f"Storage term results from ewatercycle_HBV.model",
"description":"Moddeled values",
"units": "mm"})
data_vars[name] = storage_terms_i
ds_combined = xr.Dataset(data_vars,
attrs={"title": f"HBV storage terms data over time for {n_particles} particles ",
"history": f"Storage term results from ewatercycle_HBV.model",}
)
if save:
ds_combined.to_netcdf(output_path / f'combined_ds_{current_time}.nc')
Plotting
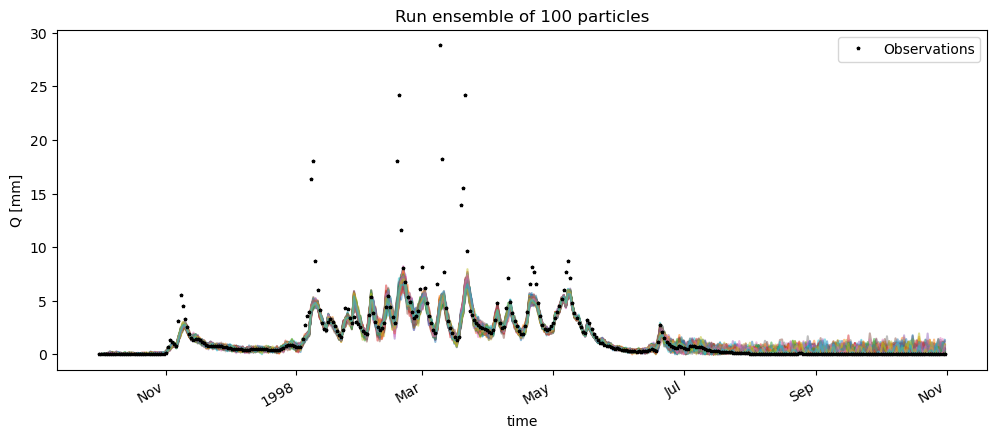
45 In:
# df_ensemble.plot()
fig, ax = plt.subplots(1,1,figsize=(12,5))
# ax.plot(ds.time.values[:n_days],ds['Q'].values[:n_days],lw=0,marker="*",ms=2.5,zorder=0,label="Observations",color="k")
# ax.plot(df.index, Q_m_in_ref[1:],label="Modelled reference Q");
ds_obs['Q'].sel(time=time).plot(ax=ax,lw=0,marker="*",ms=2.5,zorder=0,label="Observations",color='k')
ax.legend(bbox_to_anchor=(1,1))
df_ensemble.plot(ax=ax,alpha=0.5,zorder=-1,legend=False)
ax.set_ylabel("Q [mm]")
ax.set_title(f"Run ensemble of {n_particles} particles");
if save:
fig.savefig(figure_path / f"ensemble_run_for_{n_particles}_particles_{current_time}.png")
WIP: deal with ensemble collapase later
Can calculate the mea as a reference
46 In:
def calc_NSE(Qo, Qm):
QoAv = np.mean(Qo)
ErrUp = np.sum((Qm - Qo)**2)
ErrDo = np.sum((Qo - QoAv)**2)
return 1 - (ErrUp / ErrDo)
47 In:
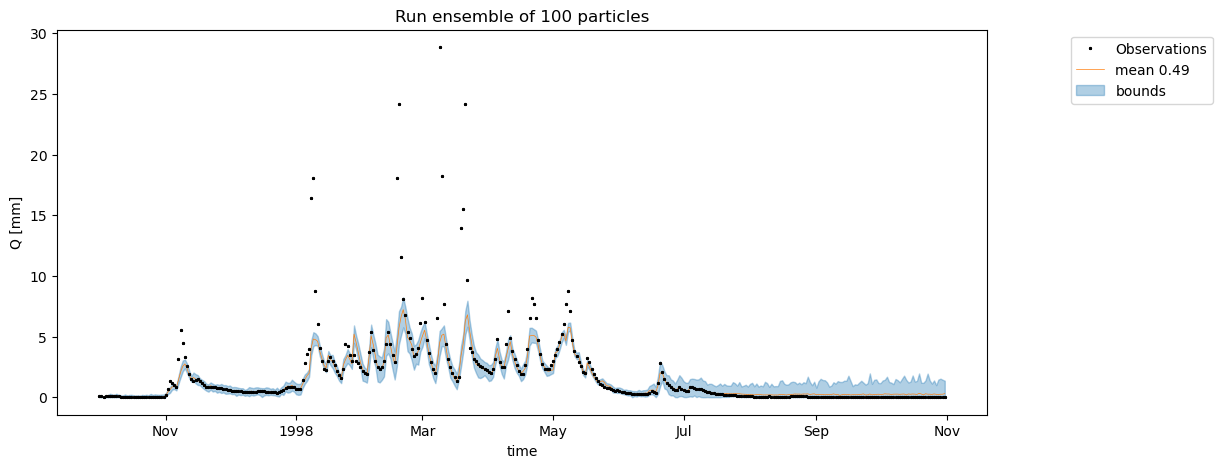
mean_ensemble = df_ensemble.T.mean()
NSE_mean_ens = calc_NSE(ds_obs['Q'].sel(time=time).values,mean_ensemble.loc[time])
48 In:
# df_ensemble.plot()
fig, ax = plt.subplots(1,1,figsize=(12,5))
# ax.plot(ds.time.values[:n_days],ds['Q'].values[:n_days],lw=0,marker="*",ms=2.5,zorder=0,label="Observations",color="k")
# ax.plot(df.index, Q_m_in_ref[1:],label="Modelled reference Q");
ds_obs['Q'].sel(time=time).plot(ax=ax,lw=0,marker="*",ms=2.0,zorder=0,label="Observations",color='k')
ax.plot(mean_ensemble,color="C1",lw=0.5,label=f"mean {NSE_mean_ens:.2f}",zorder=-1)
ax.fill_between(df_ensemble.index,df_ensemble.T.min(),df_ensemble.T.max(),color="C0", alpha=0.35,zorder=-10,label="bounds")
ax.legend(bbox_to_anchor=(1.25,1))
ax.set_ylabel("Q [mm]")
ax.set_title(f"Run ensemble of {n_particles} particles");
# ax.set_xlim((pd.Timestamp('1997-08-01'),pd.Timestamp('1998-06-01')))
if save:
fig.savefig(figure_path / f"ensemble_run_for_{n_particles}_particles_{current_time}.png",bbox_inches="tight",dpi=400);
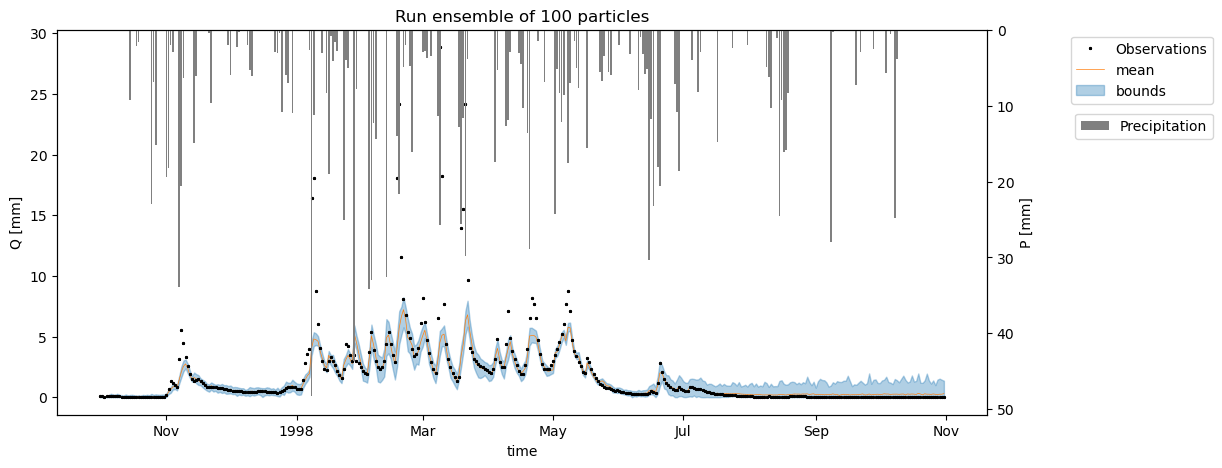
49 In:
# df_ensemble.plot()
fig, ax = plt.subplots(1,1,figsize=(12,5))
# ax.plot(ds.time.values[:n_days],ds['Q'].values[:n_days],lw=0,marker="*",ms=2.5,zorder=0,label="Observations",color="k")
# ax.plot(df.index, Q_m_in_ref[1:],label="Modelled reference Q");
ds_obs['Q'].sel(time=time).plot(ax=ax,lw=0,marker="*",ms=2.0,zorder=0,label="Observations",color='k')
ax_pr = ax.twinx()
ax_pr.invert_yaxis()
ax_pr.set_ylabel(f"P [mm]")
ax_pr.bar(df_ensemble.index,ds['pr'].values[:len(time)],zorder=-15,label="Precipitation",color="grey")
ax_pr.legend(bbox_to_anchor=(1.25,0.8))
ax.plot(mean_ensemble,color="C1",lw=0.5,label=f"mean",zorder=-1)
ax.fill_between(df_ensemble.index,df_ensemble.T.min(),df_ensemble.T.max(),color="C0", alpha=0.35,zorder=-10,label="bounds")
ax.legend(bbox_to_anchor=(1.25,1))
ax.set_ylabel("Q [mm]")
ax.set_title(f"Run ensemble of {n_particles} particles");
if save:
fig.savefig(figure_path / f"ensemble_run_for_{n_particles}_particles_bounds_P_{current_time}.png",bbox_inches="tight",dpi=400);
50 In:
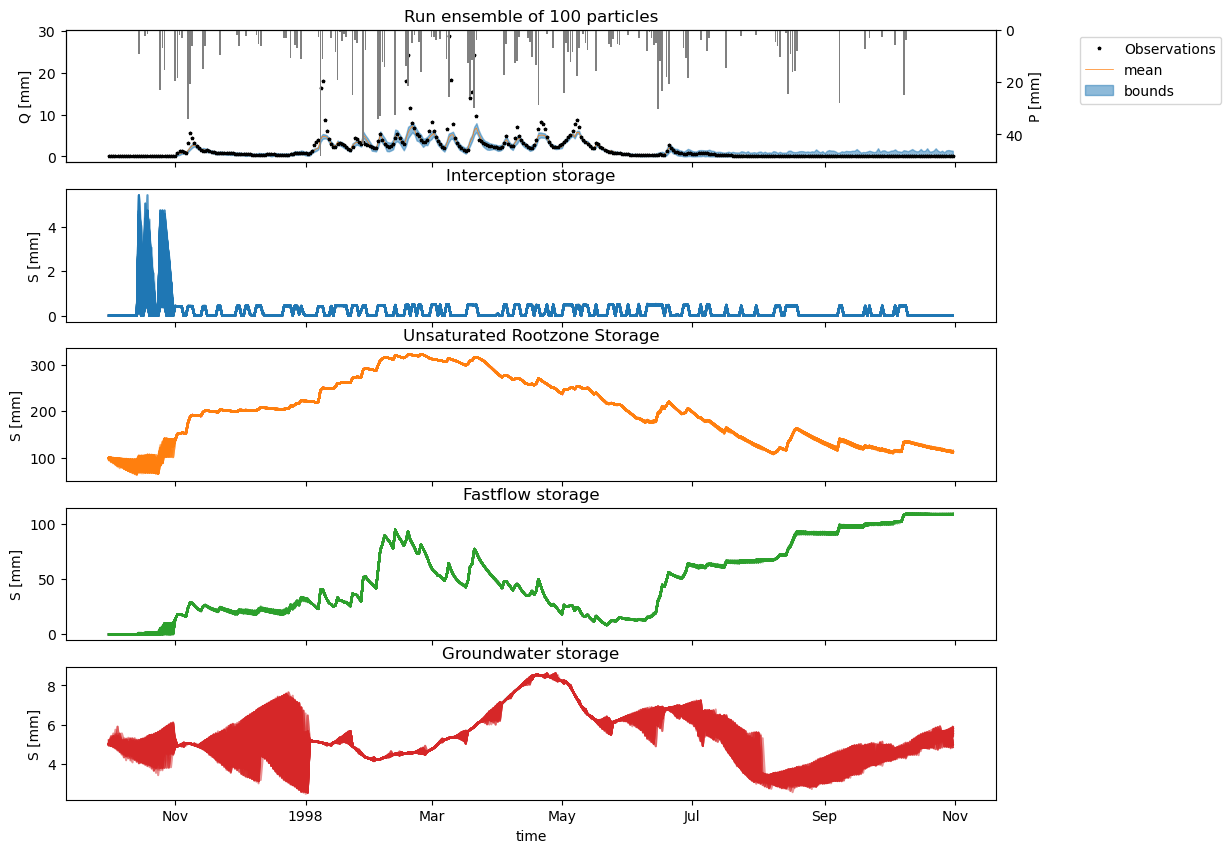
n=5
fig, axs = plt.subplots(n,1,figsize=(12,n*2),sharex=True)
ax = axs[0]
ds_obs['Q'].sel(time=time).plot(ax=ax,lw=0,marker="*",ms=2.5,zorder=0,label="Observations",color='k')
ax_pr = ax.twinx()
ax_pr.invert_yaxis()
ax_pr.set_ylabel(f"P [mm]")
ax_pr.bar(df_ensemble.index,ds['pr'].values[:len(time)],zorder=-10,label="Precipitation",color="grey")
ax.plot(mean_ensemble,color="C1",lw=0.5,label=f"mean",zorder=-1)
ax.fill_between(df_ensemble.index,df_ensemble.T.min(),df_ensemble.T.max(),color="C0", alpha=0.5,zorder=-10,label="bounds")
ax.legend(bbox_to_anchor=(1.25,1))
ax.set_ylabel("Q [mm]")
ax.set_title(f"Run ensemble of {n_particles} particles");
for i, S_name in enumerate(S_names):
for j in range(n_particles):
ds_combined[stor_names[i]].isel(EnsembleMember=j).plot(ax=axs[i+1],color=f"C{i}",alpha=0.5)
axs[i+1].set_title(S_name)
# remove all unncecearry xlabels
[ax.set_xlabel(None) for ax in axs[:-1]]
[ax.set_ylabel("S [mm]") for ax in axs[1:]]
if save:
fig.savefig(figure_path / f"ensemble_run_for__{n_particles}_particles_storages_{current_time}.png",bbox_inches="tight",dpi=400)
51 In:
fig, axs = plt.subplots(2,4,figsize=(25,10),sharex=True)
axs = axs.flatten()
for j, parameter in enumerate(param_names):
ax = axs[j]
for i in range(n_particles):
ds_combined[parameter].isel(EnsembleMember=i).plot(ax=ax,alpha=0.3)
ax.set_title(f'parameter={parameter}')# for {n_particles} Ensemble Members')
ax.set_ylabel(f'[{units[parameter]}]')
if save:
fig.savefig(figure_path / f"ensemble_run_for__{n_particles}_particles_parameters_{current_time}.png",bbox_inches="tight",dpi=400)
